


校正に関する質問
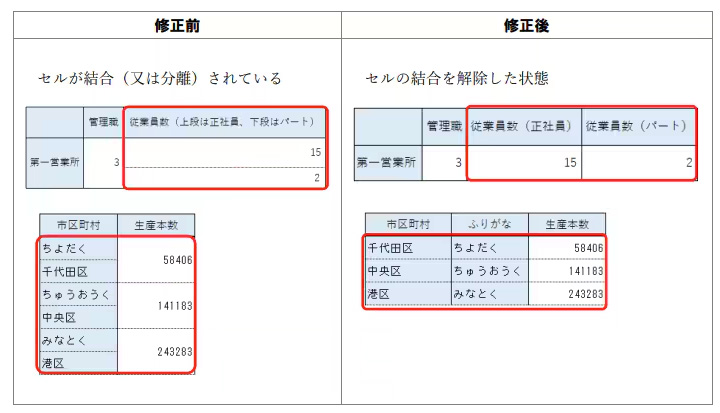
表組からデータベースに取り込むと項目がずれる
エクセルで仕上げた表からデータベースに取り込むと、途中で氏名と住所などのカラムがずれてしまうことがあります。またホームページで同じデータ構造が繰り返しているように見えるページをエクセルなどに取り込んでも、途中で表のカラムがずれてしまうとか、その逆でエクセルをhtmlにしてもずれることがあります。いずれにせよデータフォーマットを自動変換したつもりでも、変換後に全データにわたってズレのチェック・校正をしなければならないのでは、自動変換をしたメリットは半減(あるいは霧消)してしまいます。
一般にデータフォーマット変換するには、エクセルで作成したリストを基にデータベースを作る場合にcsv(カンマ区切り)でファイル出力をするような、単純構造に一度落とし込みます。その際に項目を区切っていた目印(デリミタ)が失われたり、増えてしまったりすると、変換後データは途中からずれたり、不要な項目が入ってしまうことになります。
図は、htmlをブラウザで表示したものと、そのソースコードで、html表示からも繰り返し構造をもっていることがわかります。


ソースコードでは青でくくった <li>〜</Li> の部分の構造がずっと繰り返していきます。その内で黄色で示した、カンパニーid、サムネイルpng、社名、lp-activeの項目を取り出してデータベースに取り込みたいとします。
ここにある2件のデータを見ても、lp-activeの項目数には違いがあることがわかり、単純にcsv化してはマズいことがわかります。つまり ul class の ex-lineup のところは最大の項目数を用意するか、一つの項目にまとめるような変換が必要になります。
これらから必要項目を抜き出した場合でも、最初に予見した以外のイレギュラーな記述がどこかにあるかもしれません。データベースに取り込んだ後でズレの位置を探して、抜き出したデータを修正して再度取り込むということを続ける必要があるかもしれません。何百何千とデータあると非常に時間がかかり、また作業工数も先が読めなくなります。
そこで、一挙に自動変換するのではなく、チェックや修正がしやすいように、データを分割して処理するのがいいでしょう。一挙に変換するとズレを発見しても、それが元データのどこなのかがわかりにくくなります。同じデータが重複して出て来る場合などもどちらを修正すべきか判別困難です。
例えばこの場合、html表示上で横3x縦100が1ページに表示されているとすると、300件単位で中間データに抜き出し、ズレをチェック・修正したうえで、データベースに取り込む、ということを繰り返します。つまり元データと変換データを見比べやすいような作業手順を段取りすればよいのです。変換作業はスクリプト処理が多いので分割してもそれほど面倒にはなりません。
そもそも元データに何等か構造の破たんが含まれている場合が多いので、元データに目を配るとか、元データの作成ルールを考えるべきです。エクセルについては総務省が「統計表における機械判読可能なデータの表記方法の統一ルールを策定」で注意を喚起していますので参考にしてください。
統計表における機械判読可能なデータ作成に関する表記方法
https://www.soumu.go.jp/main_content/000723626.pdf
解説:《Excelデータの作り方》総務省の「機械判読可能なデータの表記方法の統一ルール」から抜粋
https://exceljoshi.cocoo.co.jp/media/excel-date-entry-rule
一般にデータフォーマット変換するには、エクセルで作成したリストを基にデータベースを作る場合にcsv(カンマ区切り)でファイル出力をするような、単純構造に一度落とし込みます。その際に項目を区切っていた目印(デリミタ)が失われたり、増えてしまったりすると、変換後データは途中からずれたり、不要な項目が入ってしまうことになります。
図は、htmlをブラウザで表示したものと、そのソースコードで、html表示からも繰り返し構造をもっていることがわかります。

図 html表示

図 コード
ソースコードでは青でくくった <li>〜</Li> の部分の構造がずっと繰り返していきます。その内で黄色で示した、カンパニーid、サムネイルpng、社名、lp-activeの項目を取り出してデータベースに取り込みたいとします。
ここにある2件のデータを見ても、lp-activeの項目数には違いがあることがわかり、単純にcsv化してはマズいことがわかります。つまり ul class の ex-lineup のところは最大の項目数を用意するか、一つの項目にまとめるような変換が必要になります。
これらから必要項目を抜き出した場合でも、最初に予見した以外のイレギュラーな記述がどこかにあるかもしれません。データベースに取り込んだ後でズレの位置を探して、抜き出したデータを修正して再度取り込むということを続ける必要があるかもしれません。何百何千とデータあると非常に時間がかかり、また作業工数も先が読めなくなります。
そこで、一挙に自動変換するのではなく、チェックや修正がしやすいように、データを分割して処理するのがいいでしょう。一挙に変換するとズレを発見しても、それが元データのどこなのかがわかりにくくなります。同じデータが重複して出て来る場合などもどちらを修正すべきか判別困難です。
例えばこの場合、html表示上で横3x縦100が1ページに表示されているとすると、300件単位で中間データに抜き出し、ズレをチェック・修正したうえで、データベースに取り込む、ということを繰り返します。つまり元データと変換データを見比べやすいような作業手順を段取りすればよいのです。変換作業はスクリプト処理が多いので分割してもそれほど面倒にはなりません。
そもそも元データに何等か構造の破たんが含まれている場合が多いので、元データに目を配るとか、元データの作成ルールを考えるべきです。エクセルについては総務省が「統計表における機械判読可能なデータの表記方法の統一ルールを策定」で注意を喚起していますので参考にしてください。

統計表における機械判読可能なデータ作成に関する表記方法
https://www.soumu.go.jp/main_content/000723626.pdf
解説:《Excelデータの作り方》総務省の「機械判読可能なデータの表記方法の統一ルール」から抜粋
https://exceljoshi.cocoo.co.jp/media/excel-date-entry-rule
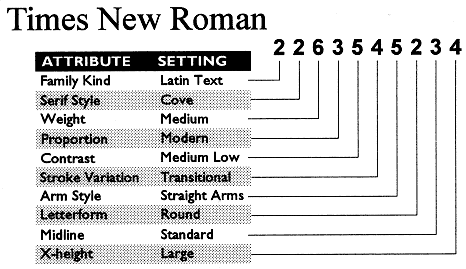
どうして類似フォントが数多くあるのか?(特に英文)
文書を作成する際にフォント指定をしようとすると、選択肢として類似フォントが多数表示され、どれを使ってよいかわからなくなる場合があります。また以前の文書作成でどれを使ったのかも覚えていられないこともあります。しかし一人の人、あるいは一つの会社でそれほど多くのフォントを使うことはあまりなく、文書作成の指針として代表的なフォントを決めておいた方がよいでしょう。
フォントの数が増えたのは、時代とともに過去の印刷用フォントの多くのものがパソコンでも使えるようになってきたからです。しかしそれは過去の印刷フォントを使っていた人、使いたい人には意味があることでも、今日の文書作成で必ずしも必要とはいえないでしょうが、一応なぜ増えたのかの説明はしておきます。その前に、フォントは見出し用(Display Type)と本文用(Body Type)に大別でき、ここでは本文用を取り上げます。
活字のフォント
特に欧文では同じ活字のフォントが異なるベンダーから提供され、しかもよく見るとデザインが微妙に異なっていることがあります。これは元の活字では同じ文字でも、活字サイズごとに源字を彫っていたので、同一文字のサイズ違いが同じデザインにはならなかったことがあります。そのために活字デザインをデジタルフォントにする際に、どのサイズの活字をベースにしたかでデザインの微差が出ます。実は文字の形は使用するサイズによって異なる非線形にデザインされた方が目で見て自然なので、こういうことが起こりました。例えば「はっぴょう」のちいさい「つ」「よ」などの促音は、小さい文字サイズで使う場合では少し大きめにデザインされました。デジタルフォントにした際にこういう配慮がどうなったかはベンダーによって異なります。どのベンダーのものを選ぶかは好みの問題でしょう。なるべく一般的なものを使うのが無難な線です。
写植のフォント
写真植字の時代にはネガの種字をレンズで工学的に変倍していました。この種字自体が太さ(weight)のバリエーションを多く持つようになっていました。
 こうなった理由は、本文文字の紙面の「黒さ」を自由に選べるようにしたからです。同じ文字デザインでありながら、短い文は太く濃く、また注釈のようなところは細く薄く、というような使い分けがありました。写植では8~10段階のWeightがありましたが、パソコンでの文書作成では4段階くらいが多いと思います。
こうなった理由は、本文文字の紙面の「黒さ」を自由に選べるようにしたからです。同じ文字デザインでありながら、短い文は太く濃く、また注釈のようなところは細く薄く、というような使い分けがありました。写植では8~10段階のWeightがありましたが、パソコンでの文書作成では4段階くらいが多いと思います。
また一つの紙面で複数の異なるデザインのフォントを混ぜて使う場合には、文字部分の黒味が均一になるようにするためにWeightの選択をしたので、多くの太さの段階が求められたともいえます。
PANOSEシステム
似たフォントを探すための仕組みとしてPANOSEシステムというフォント分類法が考えられ、パソコンで使うTrueTypeフォントはそれを使うことができます。これはWebでも扱えるようになっていて、元の文書の欧文フォントが手元のパソコンになくても、すでにインストールされているもので最も近いものに置き換えて表示・出力できるはずです。日本語に関しては実際にどの程度使われているかは不明です。
フォントの数が増えたのは、時代とともに過去の印刷用フォントの多くのものがパソコンでも使えるようになってきたからです。しかしそれは過去の印刷フォントを使っていた人、使いたい人には意味があることでも、今日の文書作成で必ずしも必要とはいえないでしょうが、一応なぜ増えたのかの説明はしておきます。その前に、フォントは見出し用(Display Type)と本文用(Body Type)に大別でき、ここでは本文用を取り上げます。
活字のフォント
特に欧文では同じ活字のフォントが異なるベンダーから提供され、しかもよく見るとデザインが微妙に異なっていることがあります。これは元の活字では同じ文字でも、活字サイズごとに源字を彫っていたので、同一文字のサイズ違いが同じデザインにはならなかったことがあります。そのために活字デザインをデジタルフォントにする際に、どのサイズの活字をベースにしたかでデザインの微差が出ます。実は文字の形は使用するサイズによって異なる非線形にデザインされた方が目で見て自然なので、こういうことが起こりました。例えば「はっぴょう」のちいさい「つ」「よ」などの促音は、小さい文字サイズで使う場合では少し大きめにデザインされました。デジタルフォントにした際にこういう配慮がどうなったかはベンダーによって異なります。どのベンダーのものを選ぶかは好みの問題でしょう。なるべく一般的なものを使うのが無難な線です。
写植のフォント
写真植字の時代にはネガの種字をレンズで工学的に変倍していました。この種字自体が太さ(weight)のバリエーションを多く持つようになっていました。
こうなった理由は、本文文字の紙面の「黒さ」を自由に選べるようにしたからです。同じ文字デザインでありながら、短い文は太く濃く、また注釈のようなところは細く薄く、というような使い分けがありました。写植では8~10段階のWeightがありましたが、パソコンでの文書作成では4段階くらいが多いと思います。また一つの紙面で複数の異なるデザインのフォントを混ぜて使う場合には、文字部分の黒味が均一になるようにするためにWeightの選択をしたので、多くの太さの段階が求められたともいえます。
PANOSEシステム
似たフォントを探すための仕組みとしてPANOSEシステムというフォント分類法が考えられ、パソコンで使うTrueTypeフォントはそれを使うことができます。これはWebでも扱えるようになっていて、元の文書の欧文フォントが手元のパソコンになくても、すでにインストールされているもので最も近いものに置き換えて表示・出力できるはずです。日本語に関しては実際にどの程度使われているかは不明です。
和文中に欧文が入る場合の注意点とは
日本語の文章(和文)と、英語ヨーロッパ各言語の文章(欧文)では、文字組版の処理の仕方が根本的に異なるために、和文中に欧文の単語やセンテンスが入る場合は、和文と欧文の境界に少し隙間を入れます。これはパソコンのメモ帳やmailでは行わないのですが、それらのテキストデータをMicrosoftWordなどに貼りこむと、自動的に隙間が入り、例えば「2022年」などの場合も2022と年の間が空いてしまってキモチ悪いと思う方もおられます。
和文と欧文では1行の行末をどう決めるかの処理が異なります。欧文は文字と文字の間に隙間は入れずに、単語と単語の間のスペースを増減して、行末を揃えます。

一方、和文は単語間はないので、第1に句読点のまわりで調整し、第2に欧文との隙間、括弧類、など、そして第3に文字間に少し隙を入れるなどして(このルールはシステムごとに違いがあります)、行末を合わせます。しかし1行に和文と欧文が混ざっていると、以下のようにうまく処理できない部分が生じることがあります。

無理やり行末を揃える処理をさせると、『ェア(主に』の行を行頭行末揃えにしてしまい、スカスカの行が出来上がります。つまり和欧混植をする場合には、段の設定で行末処理の余裕がない文字数の少ないことはしない方がよいのです。この例は3段組か4段組でしょうから、段数を減らせば『ェア(主に』の後ろに『Publisher』は入ります。
また和文と欧文では文字の揃え方の考えが異なり、縦組も横組もある和文は正方形のセンター基準でフォントデザインをしていたので、組み方もセンター揃えであったのが、欧文はベースラインを基準に文字を置いていくような活字の作りになっていました。その考え方は受け継がれている中で、現状では以下のような位置関係で和文と欧文の文字を混在させています。

実は和文フォントの中にも英数字が含まれていて、それらは和文中で記号などとして使うには揃いやすくデザインされています。例えば g j y などのディセンダ部分を短くするとか、 g h などはなるべく半角に近づける、大文字は全角に近づけるなどをしているために、 それらで欧文の文章を組むとダサい、キタナい、といわれることがあります。
逆に欧文の文字を和文中で使いすぎても、ところどころディセンダが行の下にはみ出すようなことがおき、目障りになることがあります。以下は括弧に全角和文のものと、欧文のものを使った例です。
また、同じ文字サイズでも和文フォントに対して欧文フォントは少し小さめなので、フォントサイズを変えなければバランスしないことがあります。和文フォント中に使用する欧文フォントをその都度指定するのも面倒なので、DTPでは「合成フォント」という機能があって、和文フォントと欧文フォントその他の組み合わせセットを作れるほか、組み合わせるフォントのサイズやベースライン・比率も個別に設定することができます。これを使えばデザインを崩さずに統一したフォント使いや、そのための設定が容易にできます。

和文と欧文では1行の行末をどう決めるかの処理が異なります。欧文は文字と文字の間に隙間は入れずに、単語と単語の間のスペースを増減して、行末を揃えます。

一方、和文は単語間はないので、第1に句読点のまわりで調整し、第2に欧文との隙間、括弧類、など、そして第3に文字間に少し隙を入れるなどして(このルールはシステムごとに違いがあります)、行末を合わせます。しかし1行に和文と欧文が混ざっていると、以下のようにうまく処理できない部分が生じることがあります。
無理やり行末を揃える処理をさせると、『ェア(主に』の行を行頭行末揃えにしてしまい、スカスカの行が出来上がります。つまり和欧混植をする場合には、段の設定で行末処理の余裕がない文字数の少ないことはしない方がよいのです。この例は3段組か4段組でしょうから、段数を減らせば『ェア(主に』の後ろに『Publisher』は入ります。
また和文と欧文では文字の揃え方の考えが異なり、縦組も横組もある和文は正方形のセンター基準でフォントデザインをしていたので、組み方もセンター揃えであったのが、欧文はベースラインを基準に文字を置いていくような活字の作りになっていました。その考え方は受け継がれている中で、現状では以下のような位置関係で和文と欧文の文字を混在させています。
実は和文フォントの中にも英数字が含まれていて、それらは和文中で記号などとして使うには揃いやすくデザインされています。例えば g j y などのディセンダ部分を短くするとか、 g h などはなるべく半角に近づける、大文字は全角に近づけるなどをしているために、 それらで欧文の文章を組むとダサい、キタナい、といわれることがあります。
逆に欧文の文字を和文中で使いすぎても、ところどころディセンダが行の下にはみ出すようなことがおき、目障りになることがあります。以下は括弧に全角和文のものと、欧文のものを使った例です。

また、同じ文字サイズでも和文フォントに対して欧文フォントは少し小さめなので、フォントサイズを変えなければバランスしないことがあります。和文フォント中に使用する欧文フォントをその都度指定するのも面倒なので、DTPでは「合成フォント」という機能があって、和文フォントと欧文フォントその他の組み合わせセットを作れるほか、組み合わせるフォントのサイズやベースライン・比率も個別に設定することができます。これを使えばデザインを崩さずに統一したフォント使いや、そのための設定が容易にできます。
zipファイルをWindowsとMac間でやりとりする方法
デザイナなどからMacのデータをzipファイルで受け取ってWindowsで開こうとすると、ファイル名が文字化けしていて上手く解凍できないことをよく聞きます。またDropboxやGoogle Driveで複数ファイルをダウンロードする場合は圧縮されてダウンロードされますが、この時も解凍すると文字化けしてしまう現象も同じ原理です。

これらの対策として、送る側で対処してもらう方法と、受けた側でツールを使って対応する場合があります。後者で有名なのはCubeICE(https://www.cube-soft.jp/cubeice/)というツールで、Windowsで作られたzipファイルをMacで解凍する場合の定番です。

Windowsで作られたzipファイルをMacで解凍する場合は、The Unarchiver(https://www.benricho.org/Tips/unarchiver/)があります。

しかしそもそもなぜこのようなMacとWindowsの違いがあるのでしょうか?それは日本語をコンピュータで扱う際の文字コードはJISで決まっているにもかかわらず、両OSとも当初はシフトJISを採用し、その後OSの改定の際にバラバラに「UTF-8」でエンコードに対応させてきたからです。つまりOSのバージョンによってそれぞれいろいろなやり方をとってきました。Windows10になって両OSとも「UTF-8」に揃いつつありますので、変換ツールなしでも文字化けなくやり取りする方法も生まれました。
Windowsでは2019年のアップデート(Version 1903)で、「メモ帳」アプリの文字コードでも既定でUTF-8が使われるようになりましたが、それ以前のメモ帳では「Shift-JIS」がデフォルトの文字コードでした。Windows10ではシステムに使われている文字コード(システムロケール)を、Shift-JISからUTF-8に変更することができ、そうすると今のMacOSと同じ土俵になり、文字化けは起こりません。しかし古いWindowsアプリでShift-JISでしか動かない場合は不具合が起こることがあります。
古いソフトウェア/アプリを使用しない場合は、コンピュータ環境が今後Webをベースとするクラウドへの移行しつつあり、UTF-8が主流になりますので、Shift-JISを使う環境を極力減らし、Windows10の設定をUTF-8にしていくことをおすすめします。

これらの対策として、送る側で対処してもらう方法と、受けた側でツールを使って対応する場合があります。後者で有名なのはCubeICE(https://www.cube-soft.jp/cubeice/)というツールで、Windowsで作られたzipファイルをMacで解凍する場合の定番です。
Windowsで作られたzipファイルをMacで解凍する場合は、The Unarchiver(https://www.benricho.org/Tips/unarchiver/)があります。
しかしそもそもなぜこのようなMacとWindowsの違いがあるのでしょうか?それは日本語をコンピュータで扱う際の文字コードはJISで決まっているにもかかわらず、両OSとも当初はシフトJISを採用し、その後OSの改定の際にバラバラに「UTF-8」でエンコードに対応させてきたからです。つまりOSのバージョンによってそれぞれいろいろなやり方をとってきました。Windows10になって両OSとも「UTF-8」に揃いつつありますので、変換ツールなしでも文字化けなくやり取りする方法も生まれました。
Windowsでは2019年のアップデート(Version 1903)で、「メモ帳」アプリの文字コードでも既定でUTF-8が使われるようになりましたが、それ以前のメモ帳では「Shift-JIS」がデフォルトの文字コードでした。Windows10ではシステムに使われている文字コード(システムロケール)を、Shift-JISからUTF-8に変更することができ、そうすると今のMacOSと同じ土俵になり、文字化けは起こりません。しかし古いWindowsアプリでShift-JISでしか動かない場合は不具合が起こることがあります。
古いソフトウェア/アプリを使用しない場合は、コンピュータ環境が今後Webをベースとするクラウドへの移行しつつあり、UTF-8が主流になりますので、Shift-JISを使う環境を極力減らし、Windows10の設定をUTF-8にしていくことをおすすめします。
カタログの文字が汚くなる
画面でPDF校正をしている時にはくっきり見えたはずの小さな文字が、印刷物になってから見ると不鮮明になっていることがあります。一般的なカラー印刷はCyan(青)、Magenta(紅)、Yellow(黄)、Black(黒)の4色の組み合わせでいろいろな色を表現しているので、この4色およびそれらの重ねあわせであるRed(赤)、Green(緑)、BlueViolet(青紫)は画面と同様に鮮明に印刷されます。しかしこれら7色以外の色はベタではなく網点化されるので、文字も点の構成になることを免れません。

今日の印刷物では175線(1インチあたり)の網点になりますので、2ミリ以下の小さな文字の輪郭はかなり影響を受けてしまいます。画面では一様に見えるグレーでも印刷では黒に網がかかったものになりますので、写真のようにグレーに白文字の場合に画面で拡大したものと印刷したものでは大きな違いになります。

RGBのかけあわせを薄色にする場合も、家庭用インクジェットプリンタの校正では網点化されずに出力され、適度に滲むので点の構成が目立ちませんが、オフセットの網点印刷では文字の輪郭を完全には再現できません。

とりわけCMYと黒の4色が混じる中間色では色ごとに網の角度が変わるので、単純な点構成ではなく複雑な模様で構成されます。

この場合は、もし色ごとに版が少しずれて印刷されると、文字の輪郭はさらに不鮮明になります。

印刷の色校正用のプリンタでは印刷網点のシミュレーションをできるものがあって、事前にチェックできる場合があります。しかしこれらのことはオフセットの網点印刷の宿命的な課題なので、CMY黒など原色以外の小さな文字や罫線をシャープにを鮮明に印刷するには、必要な色のインキを特色として指定して、印刷版を増やすしかありません。パッケージやラベルなどの印刷機は掛け合わせではない特色が追加できるように6色~8色同時印刷できるようにしていて、この問題に対応しています。
一般の4色印刷にせざるを得ない場合は、紙面のデザイン上で小さな文字や罫線に薄色の掛けあわせが起こらないように配慮することになります。

今日の印刷物では175線(1インチあたり)の網点になりますので、2ミリ以下の小さな文字の輪郭はかなり影響を受けてしまいます。画面では一様に見えるグレーでも印刷では黒に網がかかったものになりますので、写真のようにグレーに白文字の場合に画面で拡大したものと印刷したものでは大きな違いになります。

RGBのかけあわせを薄色にする場合も、家庭用インクジェットプリンタの校正では網点化されずに出力され、適度に滲むので点の構成が目立ちませんが、オフセットの網点印刷では文字の輪郭を完全には再現できません。

とりわけCMYと黒の4色が混じる中間色では色ごとに網の角度が変わるので、単純な点構成ではなく複雑な模様で構成されます。

この場合は、もし色ごとに版が少しずれて印刷されると、文字の輪郭はさらに不鮮明になります。

印刷の色校正用のプリンタでは印刷網点のシミュレーションをできるものがあって、事前にチェックできる場合があります。しかしこれらのことはオフセットの網点印刷の宿命的な課題なので、CMY黒など原色以外の小さな文字や罫線をシャープにを鮮明に印刷するには、必要な色のインキを特色として指定して、印刷版を増やすしかありません。パッケージやラベルなどの印刷機は掛け合わせではない特色が追加できるように6色~8色同時印刷できるようにしていて、この問題に対応しています。
一般の4色印刷にせざるを得ない場合は、紙面のデザイン上で小さな文字や罫線に薄色の掛けあわせが起こらないように配慮することになります。
バーコード、QRコードの校正はどうする
バーコードやQRコードのイメージは専用アプリを使って生成されるため、それ自体に間違いはないはずですが、印刷やプリント出力の品質、およびそこに入っているはずのデータが正しいものだったかどうかについては、何らかのチェックが必要になります。つまり印刷面と機能面の2つのチェックをすることになります。機能面については、実際に印刷されたコードを読みとって想定どうりの動作をするか確認します。まずは簡易的にはスマホで動作確認をしますが、申し込みなど複雑なフローが先にある場合は、最初から検査用のダミーのデータとそのコードを作っておき、システム的にチェックできるようにしておくとよいでしょう。
印刷については、特殊紙や一般的ではない素材にコードを印刷するとか、貼り付けるところが少し曲がっているなどの場合は、印刷物の目視検査ではなく、ちゃんとした検査器具をつかって適合性を判断することになります。特に最近はインクジェットプリンタでコードをプリントするケースが増えて、プリンタの状態とかインクが純正品ではない場合に、用紙上のイメージの滲みやカスレによるエラーが問題視される場合があります。
例えば、発送物に切手を貼らず、宛名も印字して投函し、ネットで郵便料金を決済するオンラインシッピングの場合にもバーコード、QRコードが使われます。これは発送者が自分でプリントして貼り付けるので、バリアブルプリントなどで用紙とインクの関係が不安な場合は、事前に検査しておいたほうがいいでしょう。


それに使う検査器は、主にハンディ型のものがいろいろあり、対象となるバーコード・2次元コードの種類によって相応しいものを選びます。印字品質評価に関してはISO/IEC15415規格のほか、いくつもの規格があり、それらに準じた検査を行います。こういった機器はパソコンとつないで、検査結果のレポートを作るアプリがあって、その結果を証明としてプリントアウトできます。

下に結果のレポートの例を示します。検査結果で不合格となった場合は、原因を考えて対策をします。ありがちな不合格は、コードの周りの余白不足とか不要な枠、汚れや地色、黒以外でのプリント、などではデザイン面から再検討が必要です。また利用環境の問題もあり、読み取る場所の環境光の影響や、貼り付けるところの曲がりなどの要因もあります。

印刷については、特殊紙や一般的ではない素材にコードを印刷するとか、貼り付けるところが少し曲がっているなどの場合は、印刷物の目視検査ではなく、ちゃんとした検査器具をつかって適合性を判断することになります。特に最近はインクジェットプリンタでコードをプリントするケースが増えて、プリンタの状態とかインクが純正品ではない場合に、用紙上のイメージの滲みやカスレによるエラーが問題視される場合があります。
例えば、発送物に切手を貼らず、宛名も印字して投函し、ネットで郵便料金を決済するオンラインシッピングの場合にもバーコード、QRコードが使われます。これは発送者が自分でプリントして貼り付けるので、バリアブルプリントなどで用紙とインクの関係が不安な場合は、事前に検査しておいたほうがいいでしょう。


それに使う検査器は、主にハンディ型のものがいろいろあり、対象となるバーコード・2次元コードの種類によって相応しいものを選びます。印字品質評価に関してはISO/IEC15415規格のほか、いくつもの規格があり、それらに準じた検査を行います。こういった機器はパソコンとつないで、検査結果のレポートを作るアプリがあって、その結果を証明としてプリントアウトできます。

下に結果のレポートの例を示します。検査結果で不合格となった場合は、原因を考えて対策をします。ありがちな不合格は、コードの周りの余白不足とか不要な枠、汚れや地色、黒以外でのプリント、などではデザイン面から再検討が必要です。また利用環境の問題もあり、読み取る場所の環境光の影響や、貼り付けるところの曲がりなどの要因もあります。
メールで複数の文字校正が戻った場合のまとめかた
メールでの文字校正のやりとりは、MicrosoftWordを使っている場合は元文書ファイルに赤い文字で指摘や修正を指示することもできますが、ひとつの文書に複数の校正者が赤字を入れた場合には、赤字の入った個所を見比べてまとめあげるのに、一度プリントアウトをしなければならなくなるでしょう。
また使っているフォントが校正者のパソコンにない場合には、代替フォントで表示されて、改行位置や文字間のアキなど細かな差異がチェックできなくなるかもしれません。
例えば、紛らわしいものとして、以下のようなものがあります。
全角ハイフン ‐ Hyphen
ハイフンマイナス - Hyphen‑Minus(半角のマイナス)
改行不可のハイフン ‑ Non‑Breaking Hyphen
全角マイナス − Minus Sign
二分ダッシュ – En Dash
そのため、校正用にはMicrosoftOfficeからの書き出しには、ISO 19005-1に準拠(PDF/A)をオプションで指定して、フォントを全て埋め込みにします。
またPDFにすれば、AdobeAcrobat・AdobeReaderの共有レビュー機能を使って、校正の依頼や、戻ってきた校正をひとまとめにして見比べることもできるようになります。Adobeのサイトでは共有するのにサーバーを使う場合とメールを使う場合が書かれていますが、メールだけでも使うことができます。
参考: Adobe 管理機能付きの PDF のレビューについて
仕組みは、元文書に校正指示を入れたあとでPDF保存する場合に、同時にデータファイル(.FDF)という注釈データ(校正指示)のみの軽いファイルを書き出すことができるので、校正戻しを受け取る側は、各校正者の(.FDF)を全部読み込んで、まとめて表示できるようになります。下図のAが校正者からのもの、Bが校正依頼者側の操作になります。

ただし、PDFによる校正作業は伝統的な赤字入れ(参考)の通りにはできないところがあるので、校正を依頼する側と校正者の側でPDF校正でのルールを確認しておく必要があります。
その例としては、テクニカルコミュニケーター協会によるPDF 電子校正ガイドラインがあります。
また使っているフォントが校正者のパソコンにない場合には、代替フォントで表示されて、改行位置や文字間のアキなど細かな差異がチェックできなくなるかもしれません。
例えば、紛らわしいものとして、以下のようなものがあります。
全角ハイフン ‐ Hyphen
ハイフンマイナス - Hyphen‑Minus(半角のマイナス)
改行不可のハイフン ‑ Non‑Breaking Hyphen
全角マイナス − Minus Sign
二分ダッシュ – En Dash
そのため、校正用にはMicrosoftOfficeからの書き出しには、ISO 19005-1に準拠(PDF/A)をオプションで指定して、フォントを全て埋め込みにします。
またPDFにすれば、AdobeAcrobat・AdobeReaderの共有レビュー機能を使って、校正の依頼や、戻ってきた校正をひとまとめにして見比べることもできるようになります。Adobeのサイトでは共有するのにサーバーを使う場合とメールを使う場合が書かれていますが、メールだけでも使うことができます。
参考: Adobe 管理機能付きの PDF のレビューについて


仕組みは、元文書に校正指示を入れたあとでPDF保存する場合に、同時にデータファイル(.FDF)という注釈データ(校正指示)のみの軽いファイルを書き出すことができるので、校正戻しを受け取る側は、各校正者の(.FDF)を全部読み込んで、まとめて表示できるようになります。下図のAが校正者からのもの、Bが校正依頼者側の操作になります。

ただし、PDFによる校正作業は伝統的な赤字入れ(参考)の通りにはできないところがあるので、校正を依頼する側と校正者の側でPDF校正でのルールを確認しておく必要があります。
その例としては、テクニカルコミュニケーター協会によるPDF 電子校正ガイドラインがあります。

同じ紙面ファイルでもMac/Windowsの違い、プリンタの違いで、出力の一部が異なる。
紙面が作成されてからプリントされるまでは、いくつかの過程にわけられます。
PDFのように最終イメージが保証できるファイルの場合でも、以下①~⑤のような過程における状況の差で、何らかの微妙な違いが生じることがります。
そのために紙面データの確実な再現をするには、お互いのコンピュータ環境を揃えておくとか、そうできない場合は、お互いの環境を理解して、本番出力の前にテスト出力をして確認(校正)をしておくのが無難です。要するにデジタル環境でも校正が欠かせない場合もあるのです。
プリントに関連する環境の差は以下のような要因が関連しています。実際には④のプリンタドライバーの役割が最も大きいのと思います。
①アプリの画面で紙面を作成している。 - OSやアプリのバージョン差
②アプリのデータとしてファイル保存する。- OSやアプリのバージョン差
③プリントの指定をする。 - プリンタの機能差
④プリンタにデータを送る。 - プリンタドライバーの差
⑤プリンタ内部で紙面を組み立てる。 - プリンタのファームウェア差
①は、使っているパソコンOSによって画面表示プログラムが異なることから、アプリ側でそれぞれのOSの機能にあわせた処理を行っていますが、OSもアプリもバージョンが変わることで微妙な変化がありえます。MacはQuartzという作成機能をもっていますが、Adobeアプリではその機能を使わずにアプリ独自で処理することもあり、画面で同じことをしていても、AdobeアプリとOSの機能を使うアプリでは異なるデータ構造になり、②のファイル保存の時に若干異なることがあります。
一般的なDTPはAdobeアプリを使うので、MacでもWindowsでも同じ構造のファイルを作りますが、OSに依存するアプリではMacのQuarzに対してWindowsではWPF(昔のGDIに代わって)のグラフィック機能を使っていますので、どんな環境で作成されたか知っておくのがよいでしょう。
③は、プリンタによって機能が大きく異なるために、指定項目も全く異なり、最初に作成した環境で設定した項目でも、面付け・プリント順・表裏関係などプリント時には引き継がれていないことはよくあります。そのためプリント側には別途印刷や製本の仕様を伝えて、本番印刷時に再設定してもらうことになります。
④は、アプリのデータを指定されたプリンタ用にプリンタドライバーが再処理して送り出す工程で、Postscriptデータでもプリンタドライバーが対応していれば非対応プリンターでも出力できます。一つのプリンタでも高度な機能を持つものは、目的に合わせたいろいろなプリンタドラーバーが選択できるものもあります。WindowsファイルにはWPF用を、DTPにはPostscript対応を、という使い分けが一般的です。
WindowsのWPFではパソコンのGPUの機能を使って画面表示や印刷も行なえるので、安いプリンタでも高速出力できる場合があります。
⑤は、プリンタの固有問題なので、何か不具合が起こってもその場では対処できず、④③②①を遡ってデータの修正をするしか手の打ちようがないでしょう。
こういった問題をなるべく避けるために、オフセット印刷が目的の場合は、PDF/X-1aやPDF/X-3のようなデータのチェックに対応したファイルを最初から作ることが行われています。(参考 Q : プリフライト・チェックと校正は違うのですか?)
例えばMicrosoftOfficeでpdfを指定してファイル保存をすると、フォントによってはビットマップになってしまう場合があり、高解像度の印刷には不向きになります。これらはプリフライトチェックによって事前に判別できます。
PDFのように最終イメージが保証できるファイルの場合でも、以下①~⑤のような過程における状況の差で、何らかの微妙な違いが生じることがります。
そのために紙面データの確実な再現をするには、お互いのコンピュータ環境を揃えておくとか、そうできない場合は、お互いの環境を理解して、本番出力の前にテスト出力をして確認(校正)をしておくのが無難です。要するにデジタル環境でも校正が欠かせない場合もあるのです。
プリントに関連する環境の差は以下のような要因が関連しています。実際には④のプリンタドライバーの役割が最も大きいのと思います。
①アプリの画面で紙面を作成している。 - OSやアプリのバージョン差
②アプリのデータとしてファイル保存する。- OSやアプリのバージョン差
③プリントの指定をする。 - プリンタの機能差
④プリンタにデータを送る。 - プリンタドライバーの差
⑤プリンタ内部で紙面を組み立てる。 - プリンタのファームウェア差
①は、使っているパソコンOSによって画面表示プログラムが異なることから、アプリ側でそれぞれのOSの機能にあわせた処理を行っていますが、OSもアプリもバージョンが変わることで微妙な変化がありえます。MacはQuartzという作成機能をもっていますが、Adobeアプリではその機能を使わずにアプリ独自で処理することもあり、画面で同じことをしていても、AdobeアプリとOSの機能を使うアプリでは異なるデータ構造になり、②のファイル保存の時に若干異なることがあります。
一般的なDTPはAdobeアプリを使うので、MacでもWindowsでも同じ構造のファイルを作りますが、OSに依存するアプリではMacのQuarzに対してWindowsではWPF(昔のGDIに代わって)のグラフィック機能を使っていますので、どんな環境で作成されたか知っておくのがよいでしょう。
③は、プリンタによって機能が大きく異なるために、指定項目も全く異なり、最初に作成した環境で設定した項目でも、面付け・プリント順・表裏関係などプリント時には引き継がれていないことはよくあります。そのためプリント側には別途印刷や製本の仕様を伝えて、本番印刷時に再設定してもらうことになります。
④は、アプリのデータを指定されたプリンタ用にプリンタドライバーが再処理して送り出す工程で、Postscriptデータでもプリンタドライバーが対応していれば非対応プリンターでも出力できます。一つのプリンタでも高度な機能を持つものは、目的に合わせたいろいろなプリンタドラーバーが選択できるものもあります。WindowsファイルにはWPF用を、DTPにはPostscript対応を、という使い分けが一般的です。
WindowsのWPFではパソコンのGPUの機能を使って画面表示や印刷も行なえるので、安いプリンタでも高速出力できる場合があります。
⑤は、プリンタの固有問題なので、何か不具合が起こってもその場では対処できず、④③②①を遡ってデータの修正をするしか手の打ちようがないでしょう。
こういった問題をなるべく避けるために、オフセット印刷が目的の場合は、PDF/X-1aやPDF/X-3のようなデータのチェックに対応したファイルを最初から作ることが行われています。(参考 Q : プリフライト・チェックと校正は違うのですか?)
例えばMicrosoftOfficeでpdfを指定してファイル保存をすると、フォントによってはビットマップになってしまう場合があり、高解像度の印刷には不向きになります。これらはプリフライトチェックによって事前に判別できます。
多くの校正がピークに集中するのを短時間で処理したい。
一般に印刷に下版するリミットが決まっているのに、原稿が集まってくるのが遅く集中するので、校正作業が工程のボトルネックになりがちです。これらに対する取り組みとして、いくつかの例を紹介します。
学会や学術会議などに配布する印刷物で多くの発表者・著者の原稿が一気に集まってくる場合に、事務局の人員能力ではイベントに向けての準備も同時にあって、原稿の受け渡しから印刷所とのやり取りも対応できなくなるので、著者自身に入力してもらって、Web画面で原稿入稿や修正をして、自動組版の結果を画面を確認してもらい、冊子のPDFを作って印刷にまわすシステムが使われます。
基本的にはすべてがオンラインの作業となり、複数の人が同時並行的に入稿や校正をすることが可能になります。また著者が校正漏れを後で発見した際にも、オンラインで自分で校正の直しを行うことができるので、時間の許す限り編集が可能となります。
カタログなどDTPの冊子中にある値段や消費税などを新しいものに一斉に変更する場合も、自動組版では一斉変更すべきところにあらかじめタグを入れておいて、別途変更内容のファイルだけを用意して、一挙に全ページにその変更データを差し替えることが可能です。校正は変更内容のファイルで終了させておけば、個別ページは自動処理だけで作業は終わります。
同様に紙面とデータ部分を区別しておいて、紙面にデータベースの更新された二様を反映させるような、原稿の自動更新をする例があります。
カタログに原稿を提供する会社が複数あって、校正紙を複数配布すると、それぞれに赤が入っても戻ってくるので、校正作業が入り乱れてしまうことがあります。この場合もWebで入稿するオンラインの修正が可能な自動組版なら、同時期に校正が重なっても統合的に作業が進められるようになります。
学会や学術会議などに配布する印刷物で多くの発表者・著者の原稿が一気に集まってくる場合に、事務局の人員能力ではイベントに向けての準備も同時にあって、原稿の受け渡しから印刷所とのやり取りも対応できなくなるので、著者自身に入力してもらって、Web画面で原稿入稿や修正をして、自動組版の結果を画面を確認してもらい、冊子のPDFを作って印刷にまわすシステムが使われます。
基本的にはすべてがオンラインの作業となり、複数の人が同時並行的に入稿や校正をすることが可能になります。また著者が校正漏れを後で発見した際にも、オンラインで自分で校正の直しを行うことができるので、時間の許す限り編集が可能となります。
カタログなどDTPの冊子中にある値段や消費税などを新しいものに一斉に変更する場合も、自動組版では一斉変更すべきところにあらかじめタグを入れておいて、別途変更内容のファイルだけを用意して、一挙に全ページにその変更データを差し替えることが可能です。校正は変更内容のファイルで終了させておけば、個別ページは自動処理だけで作業は終わります。
同様に紙面とデータ部分を区別しておいて、紙面にデータベースの更新された二様を反映させるような、原稿の自動更新をする例があります。
カタログに原稿を提供する会社が複数あって、校正紙を複数配布すると、それぞれに赤が入っても戻ってくるので、校正作業が入り乱れてしまうことがあります。この場合もWebで入稿するオンラインの修正が可能な自動組版なら、同時期に校正が重なっても統合的に作業が進められるようになります。
電子書籍を制作する場合に校正はどのようにすればよいのか?
文字校正と組版のチェックの他に電子書籍端末などの操作が正しくできるかということも校正の中に含まれます。
現在は電子書籍のフォーマットはEPUB3が標準ですが、以前にドットブックやXMDFなど他のフォーマットで作成されていた原稿を変換した場合が多く、不適切なタグが文字化けや組版上の不具合になるで、紙の書籍の校正とは異なって、ツールを使って必要な仕様に合致しているかの検証を行います。
またEPUBで入稿しても Amazon Kindle のように製品になった場合は独自形式に変換されている場合があり、EPUB段階でのチェックだけでなく、最終製品におけるチェックも必要になります。
電子書籍端末やタブレットで使うリーダーソフトごとにEPUBのレンダリングエンジンが異なるので、同じソースコードでも表示の差も起こります。これらのリーダーの固有の特徴は一覧化しておいて、許容範囲の中での相違かどうかを確認します。
元原稿や操作面は目視と同じく人が行いますが、EPUBソースコードにどのようにタグが入っているのかをチェックするのは従来の校正作業とは別に、製作段階で検証しておく必要があります。
現在は電子書籍のフォーマットはEPUB3が標準ですが、以前にドットブックやXMDFなど他のフォーマットで作成されていた原稿を変換した場合が多く、不適切なタグが文字化けや組版上の不具合になるで、紙の書籍の校正とは異なって、ツールを使って必要な仕様に合致しているかの検証を行います。
またEPUBで入稿しても Amazon Kindle のように製品になった場合は独自形式に変換されている場合があり、EPUB段階でのチェックだけでなく、最終製品におけるチェックも必要になります。
電子書籍端末やタブレットで使うリーダーソフトごとにEPUBのレンダリングエンジンが異なるので、同じソースコードでも表示の差も起こります。これらのリーダーの固有の特徴は一覧化しておいて、許容範囲の中での相違かどうかを確認します。
元原稿や操作面は目視と同じく人が行いますが、EPUBソースコードにどのようにタグが入っているのかをチェックするのは従来の校正作業とは別に、製作段階で検証しておく必要があります。
写真をパソコン画面で見た時と印刷した場合の色が合わない
画面はRGBの発光の組合せにより、紙面ではCMYインキの組合せにより、いろいろな色を出しているという原理的な違いはありますが、さまざまな色の対応を自動的にとるためにカラーマネジメントのシステムが使われています。パソコンのプリンタでは紙の質を指定することで、紙による発色範囲が異なってもだいたい相似的なカラーバランスになるように設定されています。
しかしオフセット印刷のようにパソコンと直結していないところでは、このカラーマネジメントは無効で、むしろオフセット印刷用のカラーマネジメントにパソコンを合わせるような使い方が必要になります。
カラー製版用のDTPでは、一般のパソコンの画面とは別に、印刷用途にカラーマネジメントされた画面で作業するようになっていて、そこではオフセット印刷と相似的なカラーバランスになるようにできます。そこから色校正用にプリンタしたものによって印刷仕上がりを予測することになります。
印刷用のカラーマネジメントでは、あらかじめ印刷インキの発色範囲に合わせた画面で画像を確認することと、画像出力時には印刷用紙の特性に合わせた処理をして、色校正と本刷りを近づけます。
パソコンのプリンタと同様に、とりわけ紙の種類・特性による発色の違いが大きいので、以前印刷したデータで異なる紙に印刷すれば発色が異なってしまいます。特に光沢のあるアートコート紙に比べてマット系の用紙は色が沈む傾向にありますので、標準的な用紙を使わない場合には、実際に使用する用紙で色校正してもらって確認する必要があるでしょう。
しかしオフセット印刷のようにパソコンと直結していないところでは、このカラーマネジメントは無効で、むしろオフセット印刷用のカラーマネジメントにパソコンを合わせるような使い方が必要になります。
カラー製版用のDTPでは、一般のパソコンの画面とは別に、印刷用途にカラーマネジメントされた画面で作業するようになっていて、そこではオフセット印刷と相似的なカラーバランスになるようにできます。そこから色校正用にプリンタしたものによって印刷仕上がりを予測することになります。
印刷用のカラーマネジメントでは、あらかじめ印刷インキの発色範囲に合わせた画面で画像を確認することと、画像出力時には印刷用紙の特性に合わせた処理をして、色校正と本刷りを近づけます。
パソコンのプリンタと同様に、とりわけ紙の種類・特性による発色の違いが大きいので、以前印刷したデータで異なる紙に印刷すれば発色が異なってしまいます。特に光沢のあるアートコート紙に比べてマット系の用紙は色が沈む傾向にありますので、標準的な用紙を使わない場合には、実際に使用する用紙で色校正してもらって確認する必要があるでしょう。
















新着情報





ランキング






