


文字に関する質問
バラバラのファイル名を整理したい
ファイル名が長く取れるようになったことと、アプリのファイル管理が無意味な名前に置き換えることが多いので、人間には覚えられないファイル名を扱うことが多くなっています。「Q:バックアップデータを利用しやすくするには」では、naming conventions (命名規則)に触れていますが、そのような運用をするには、名前の管理が重要です。そうすると後日に再利用できるようになります。
また「Q:いつ何をバックアップしたらよいのか?」では、撮影したり、受け取ったり、描き起こし・クリエイトした「無加工データ」の段階から、内容チェックして必要な修正をした制作のスタート段階を区別していますが、その段階ではワークフローに沿った命名規則が必要になります。
それぞれの段階でのバックアップに先だって、ファイル名の混乱が起きないように、不適切なファイル名はツールを使って修正しておくのが良いでしょう。ファイル名を変更するのはWindows/DOSでは”rename”というコマンドがありますが、結構間違えやすいので、専用アプリを使うのがおすすめです。
例えばWindows版の無料アプリ”Flexible Renamer.exe”では、下図のように既存のファイル名の文字列をかなり自由に一括変換することができます。ありがちなのは、区切り文字として「202406-12a」「202406_33d」のように、作業者によって「ハイフン」「アンダーバー」の使い方が異なっていたり、使用禁止のはずの半角カタカナが混じっていたり、フリ仮名で「カタカナ・ひらがな」が不統一であったりするのを、簡単に統一できます。
この場合、(A)のように”100NIKON”というフォルダのすべてのファイルに”DSCN”という文字列を、期間をあらわす”202406”に置き換えたいとすると、Flexible Renamer.exeを起動して右の窓に”100NIKON”フォルダをドラッグ&ドロップ(B)して、(C)の文字列変換を選び、(D)のところに「変換前の文字列」「変換後の文字列」を入れて、リネームを実行します。

また、全くてんでんばらばらなファイル名では内容を想像できない場合など、何らかの意味を持たせたファイル名に一括変換するには、エクセルなどでファイル名の新旧対照表を作っておいて、バッチファイルで一気に変換することができます。
まず画像のファイル名をテキストとして取得(操作としては、dir /b>namelist.txt などのように)し、サムネイルなどを見ながら新ファイル名を対照表に入れます。
これを csv形式のファイルで例えば”newname.csv”として保存し、 以下のようなバッチファイルを用意します。
FOR /F "tokens=1,2 delims=," %%a in (newname.csv) do REN %%a %%b
これは”newname.csv”の中からカンマで区切られた2つの要素を取り出して、REN(リネーム)を実行させるさせることを連続で行うものです。例えば上の1行を”newname.bat”と保存して実行すれば、一気に新ファイル名が出来上がります。
こういった操作は何か手違いがあると取り返しのつかない事になるリスクもありますので、あくまでどこかに作業用のフォルダを用意して、そこに全データをコピーして失敗しても被害がないような環境で実行したほうがよいでしょう。例えば無加工の入稿画像をバックアップして、そこで実行して、うまくいっていたら戻して加工するなどです。
また「Q:いつ何をバックアップしたらよいのか?」では、撮影したり、受け取ったり、描き起こし・クリエイトした「無加工データ」の段階から、内容チェックして必要な修正をした制作のスタート段階を区別していますが、その段階ではワークフローに沿った命名規則が必要になります。
それぞれの段階でのバックアップに先だって、ファイル名の混乱が起きないように、不適切なファイル名はツールを使って修正しておくのが良いでしょう。ファイル名を変更するのはWindows/DOSでは”rename”というコマンドがありますが、結構間違えやすいので、専用アプリを使うのがおすすめです。
例えばWindows版の無料アプリ”Flexible Renamer.exe”では、下図のように既存のファイル名の文字列をかなり自由に一括変換することができます。ありがちなのは、区切り文字として「202406-12a」「202406_33d」のように、作業者によって「ハイフン」「アンダーバー」の使い方が異なっていたり、使用禁止のはずの半角カタカナが混じっていたり、フリ仮名で「カタカナ・ひらがな」が不統一であったりするのを、簡単に統一できます。
この場合、(A)のように”100NIKON”というフォルダのすべてのファイルに”DSCN”という文字列を、期間をあらわす”202406”に置き換えたいとすると、Flexible Renamer.exeを起動して右の窓に”100NIKON”フォルダをドラッグ&ドロップ(B)して、(C)の文字列変換を選び、(D)のところに「変換前の文字列」「変換後の文字列」を入れて、リネームを実行します。
また、全くてんでんばらばらなファイル名では内容を想像できない場合など、何らかの意味を持たせたファイル名に一括変換するには、エクセルなどでファイル名の新旧対照表を作っておいて、バッチファイルで一気に変換することができます。
まず画像のファイル名をテキストとして取得(操作としては、dir /b>namelist.txt などのように)し、サムネイルなどを見ながら新ファイル名を対照表に入れます。
これを csv形式のファイルで例えば”newname.csv”として保存し、 以下のようなバッチファイルを用意します。
FOR /F "tokens=1,2 delims=," %%a in (newname.csv) do REN %%a %%b
これは”newname.csv”の中からカンマで区切られた2つの要素を取り出して、REN(リネーム)を実行させるさせることを連続で行うものです。例えば上の1行を”newname.bat”と保存して実行すれば、一気に新ファイル名が出来上がります。
こういった操作は何か手違いがあると取り返しのつかない事になるリスクもありますので、あくまでどこかに作業用のフォルダを用意して、そこに全データをコピーして失敗しても被害がないような環境で実行したほうがよいでしょう。例えば無加工の入稿画像をバックアップして、そこで実行して、うまくいっていたら戻して加工するなどです。
クラウドに置いたテキストファイルが文字化けする
クラウド上にファイルを置いてPCやスマホ・タブレットで情報共有することが多くなっています。原稿のやり取りにもクラウド経由での作業が増えています。一般的なネット上のストレージとして、OneDrive、Googleドライブ、DropBoxなどが有名ですが、そこにある文書をスマホで開いたら次のようになって読めないことがあります。

しかしWindowsPCではちゃんと読める場合、Windowsで再度保存する際に文字コードを UTF-8 に指定すると、スマホで読めるはずです。この場合、最初にWindowsなどで文書作成をした際に、過去との互換性を考慮して、無指定では文字コードがシフトJISが扱える「ANSI」になっていたと考えられます。
最近のWindowsアプリでは文字コードがシフトJISではなく、最初からunicodeになっているものが多いです。例えばファイル名に空白文字が使えているのはシフトJISではなくunicodeを使っているアプリです。unicode対応なら世界中の多くの言語・文字が扱えます。読めない文字が何語なのかわからない場合は、テキストファイルをInternet Explorerのウィンドウにドラッグ&ドロップして、言語をチェックすることができます。同様に文字化けしたファイルもInternet Explorerで開くとunicode か シフトJISかがわかりますし、異なるコードを選択して保存すれば、コード変換がされます。

しかし、現実問題としてInternet Explorerはそれほど使われていないので、同等の変換はWindowsのメモ帳を使うのが良いでしょう。つまり、(A)のような文字化けした文字列をメモ帳にカット&ペーストして、(B)文字コードにANSIを選択して保存すると、(C)シフトJISの文書になって読めるようになります。

冒頭のスマホで化けている場合は、逆にAndroidなどではシフトJISの文書が読めないからで、クラウドに文書を載せる場合は、なるべくUTF-8を使うのがおすすめです。今日UTF-8で作った文書は古いWindows ソフトウェア以外ではどこでも読めるはずです。
またネット上には任意の文字列を意図的に文字化けさせたり、文字化けの復元を試みるアプリもあります。
(例 https://tools.m-bsys.com/dev_tools/char_corruption.php)

文字化けした文字列をカット&ペーストして、変換や復元をやってみると、だいたいどんな化け方をすると、何が原因かがつかめるようになります。例えば、古いzip圧縮アプリ(Lhaplusなど)で日本語ファイル名などを含むファイルを扱って、ファイル名が化けた場合に、これで変換して読めるようにできます。zip圧縮を扱うのは最近のWindowsに備わっているExplolerの機能を使う方が確実です。
しかしWindowsPCではちゃんと読める場合、Windowsで再度保存する際に文字コードを UTF-8 に指定すると、スマホで読めるはずです。この場合、最初にWindowsなどで文書作成をした際に、過去との互換性を考慮して、無指定では文字コードがシフトJISが扱える「ANSI」になっていたと考えられます。
最近のWindowsアプリでは文字コードがシフトJISではなく、最初からunicodeになっているものが多いです。例えばファイル名に空白文字が使えているのはシフトJISではなくunicodeを使っているアプリです。unicode対応なら世界中の多くの言語・文字が扱えます。読めない文字が何語なのかわからない場合は、テキストファイルをInternet Explorerのウィンドウにドラッグ&ドロップして、言語をチェックすることができます。同様に文字化けしたファイルもInternet Explorerで開くとunicode か シフトJISかがわかりますし、異なるコードを選択して保存すれば、コード変換がされます。
しかし、現実問題としてInternet Explorerはそれほど使われていないので、同等の変換はWindowsのメモ帳を使うのが良いでしょう。つまり、(A)のような文字化けした文字列をメモ帳にカット&ペーストして、(B)文字コードにANSIを選択して保存すると、(C)シフトJISの文書になって読めるようになります。
冒頭のスマホで化けている場合は、逆にAndroidなどではシフトJISの文書が読めないからで、クラウドに文書を載せる場合は、なるべくUTF-8を使うのがおすすめです。今日UTF-8で作った文書は古いWindows ソフトウェア以外ではどこでも読めるはずです。
またネット上には任意の文字列を意図的に文字化けさせたり、文字化けの復元を試みるアプリもあります。
(例 https://tools.m-bsys.com/dev_tools/char_corruption.php)
文字化けした文字列をカット&ペーストして、変換や復元をやってみると、だいたいどんな化け方をすると、何が原因かがつかめるようになります。例えば、古いzip圧縮アプリ(Lhaplusなど)で日本語ファイル名などを含むファイルを扱って、ファイル名が化けた場合に、これで変換して読めるようにできます。zip圧縮を扱うのは最近のWindowsに備わっているExplolerの機能を使う方が確実です。
どうして類似フォントが数多くあるのか?(特に英文)
文書を作成する際にフォント指定をしようとすると、選択肢として類似フォントが多数表示され、どれを使ってよいかわからなくなる場合があります。また以前の文書作成でどれを使ったのかも覚えていられないこともあります。しかし一人の人、あるいは一つの会社でそれほど多くのフォントを使うことはあまりなく、文書作成の指針として代表的なフォントを決めておいた方がよいでしょう。
フォントの数が増えたのは、時代とともに過去の印刷用フォントの多くのものがパソコンでも使えるようになってきたからです。しかしそれは過去の印刷フォントを使っていた人、使いたい人には意味があることでも、今日の文書作成で必ずしも必要とはいえないでしょうが、一応なぜ増えたのかの説明はしておきます。その前に、フォントは見出し用(Display Type)と本文用(Body Type)に大別でき、ここでは本文用を取り上げます。
活字のフォント
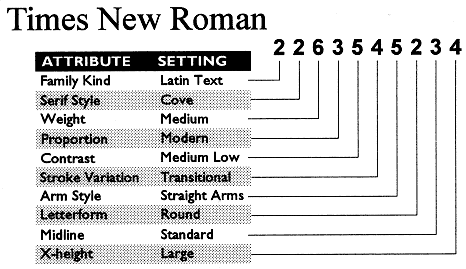
特に欧文では同じ活字のフォントが異なるベンダーから提供され、しかもよく見るとデザインが微妙に異なっていることがあります。これは元の活字では同じ文字でも、活字サイズごとに源字を彫っていたので、同一文字のサイズ違いが同じデザインにはならなかったことがあります。そのために活字デザインをデジタルフォントにする際に、どのサイズの活字をベースにしたかでデザインの微差が出ます。実は文字の形は使用するサイズによって異なる非線形にデザインされた方が目で見て自然なので、こういうことが起こりました。例えば「はっぴょう」のちいさい「つ」「よ」などの促音は、小さい文字サイズで使う場合では少し大きめにデザインされました。デジタルフォントにした際にこういう配慮がどうなったかはベンダーによって異なります。どのベンダーのものを選ぶかは好みの問題でしょう。なるべく一般的なものを使うのが無難な線です。
写植のフォント
写真植字の時代にはネガの種字をレンズで工学的に変倍していました。この種字自体が太さ(weight)のバリエーションを多く持つようになっていました。
 こうなった理由は、本文文字の紙面の「黒さ」を自由に選べるようにしたからです。同じ文字デザインでありながら、短い文は太く濃く、また注釈のようなところは細く薄く、というような使い分けがありました。写植では8~10段階のWeightがありましたが、パソコンでの文書作成では4段階くらいが多いと思います。
こうなった理由は、本文文字の紙面の「黒さ」を自由に選べるようにしたからです。同じ文字デザインでありながら、短い文は太く濃く、また注釈のようなところは細く薄く、というような使い分けがありました。写植では8~10段階のWeightがありましたが、パソコンでの文書作成では4段階くらいが多いと思います。
また一つの紙面で複数の異なるデザインのフォントを混ぜて使う場合には、文字部分の黒味が均一になるようにするためにWeightの選択をしたので、多くの太さの段階が求められたともいえます。
PANOSEシステム
似たフォントを探すための仕組みとしてPANOSEシステムというフォント分類法が考えられ、パソコンで使うTrueTypeフォントはそれを使うことができます。これはWebでも扱えるようになっていて、元の文書の欧文フォントが手元のパソコンになくても、すでにインストールされているもので最も近いものに置き換えて表示・出力できるはずです。日本語に関しては実際にどの程度使われているかは不明です。
フォントの数が増えたのは、時代とともに過去の印刷用フォントの多くのものがパソコンでも使えるようになってきたからです。しかしそれは過去の印刷フォントを使っていた人、使いたい人には意味があることでも、今日の文書作成で必ずしも必要とはいえないでしょうが、一応なぜ増えたのかの説明はしておきます。その前に、フォントは見出し用(Display Type)と本文用(Body Type)に大別でき、ここでは本文用を取り上げます。
活字のフォント
特に欧文では同じ活字のフォントが異なるベンダーから提供され、しかもよく見るとデザインが微妙に異なっていることがあります。これは元の活字では同じ文字でも、活字サイズごとに源字を彫っていたので、同一文字のサイズ違いが同じデザインにはならなかったことがあります。そのために活字デザインをデジタルフォントにする際に、どのサイズの活字をベースにしたかでデザインの微差が出ます。実は文字の形は使用するサイズによって異なる非線形にデザインされた方が目で見て自然なので、こういうことが起こりました。例えば「はっぴょう」のちいさい「つ」「よ」などの促音は、小さい文字サイズで使う場合では少し大きめにデザインされました。デジタルフォントにした際にこういう配慮がどうなったかはベンダーによって異なります。どのベンダーのものを選ぶかは好みの問題でしょう。なるべく一般的なものを使うのが無難な線です。
写植のフォント
写真植字の時代にはネガの種字をレンズで工学的に変倍していました。この種字自体が太さ(weight)のバリエーションを多く持つようになっていました。
こうなった理由は、本文文字の紙面の「黒さ」を自由に選べるようにしたからです。同じ文字デザインでありながら、短い文は太く濃く、また注釈のようなところは細く薄く、というような使い分けがありました。写植では8~10段階のWeightがありましたが、パソコンでの文書作成では4段階くらいが多いと思います。また一つの紙面で複数の異なるデザインのフォントを混ぜて使う場合には、文字部分の黒味が均一になるようにするためにWeightの選択をしたので、多くの太さの段階が求められたともいえます。
PANOSEシステム
似たフォントを探すための仕組みとしてPANOSEシステムというフォント分類法が考えられ、パソコンで使うTrueTypeフォントはそれを使うことができます。これはWebでも扱えるようになっていて、元の文書の欧文フォントが手元のパソコンになくても、すでにインストールされているもので最も近いものに置き換えて表示・出力できるはずです。日本語に関しては実際にどの程度使われているかは不明です。
和文中に欧文が入る場合の注意点とは
日本語の文章(和文)と、英語ヨーロッパ各言語の文章(欧文)では、文字組版の処理の仕方が根本的に異なるために、和文中に欧文の単語やセンテンスが入る場合は、和文と欧文の境界に少し隙間を入れます。これはパソコンのメモ帳やmailでは行わないのですが、それらのテキストデータをMicrosoftWordなどに貼りこむと、自動的に隙間が入り、例えば「2022年」などの場合も2022と年の間が空いてしまってキモチ悪いと思う方もおられます。
和文と欧文では1行の行末をどう決めるかの処理が異なります。欧文は文字と文字の間に隙間は入れずに、単語と単語の間のスペースを増減して、行末を揃えます。

一方、和文は単語間はないので、第1に句読点のまわりで調整し、第2に欧文との隙間、括弧類、など、そして第3に文字間に少し隙を入れるなどして(このルールはシステムごとに違いがあります)、行末を合わせます。しかし1行に和文と欧文が混ざっていると、以下のようにうまく処理できない部分が生じることがあります。

無理やり行末を揃える処理をさせると、『ェア(主に』の行を行頭行末揃えにしてしまい、スカスカの行が出来上がります。つまり和欧混植をする場合には、段の設定で行末処理の余裕がない文字数の少ないことはしない方がよいのです。この例は3段組か4段組でしょうから、段数を減らせば『ェア(主に』の後ろに『Publisher』は入ります。
また和文と欧文では文字の揃え方の考えが異なり、縦組も横組もある和文は正方形のセンター基準でフォントデザインをしていたので、組み方もセンター揃えであったのが、欧文はベースラインを基準に文字を置いていくような活字の作りになっていました。その考え方は受け継がれている中で、現状では以下のような位置関係で和文と欧文の文字を混在させています。

実は和文フォントの中にも英数字が含まれていて、それらは和文中で記号などとして使うには揃いやすくデザインされています。例えば g j y などのディセンダ部分を短くするとか、 g h などはなるべく半角に近づける、大文字は全角に近づけるなどをしているために、 それらで欧文の文章を組むとダサい、キタナい、といわれることがあります。
逆に欧文の文字を和文中で使いすぎても、ところどころディセンダが行の下にはみ出すようなことがおき、目障りになることがあります。以下は括弧に全角和文のものと、欧文のものを使った例です。
また、同じ文字サイズでも和文フォントに対して欧文フォントは少し小さめなので、フォントサイズを変えなければバランスしないことがあります。和文フォント中に使用する欧文フォントをその都度指定するのも面倒なので、DTPでは「合成フォント」という機能があって、和文フォントと欧文フォントその他の組み合わせセットを作れるほか、組み合わせるフォントのサイズやベースライン・比率も個別に設定することができます。これを使えばデザインを崩さずに統一したフォント使いや、そのための設定が容易にできます。

和文と欧文では1行の行末をどう決めるかの処理が異なります。欧文は文字と文字の間に隙間は入れずに、単語と単語の間のスペースを増減して、行末を揃えます。

一方、和文は単語間はないので、第1に句読点のまわりで調整し、第2に欧文との隙間、括弧類、など、そして第3に文字間に少し隙を入れるなどして(このルールはシステムごとに違いがあります)、行末を合わせます。しかし1行に和文と欧文が混ざっていると、以下のようにうまく処理できない部分が生じることがあります。
無理やり行末を揃える処理をさせると、『ェア(主に』の行を行頭行末揃えにしてしまい、スカスカの行が出来上がります。つまり和欧混植をする場合には、段の設定で行末処理の余裕がない文字数の少ないことはしない方がよいのです。この例は3段組か4段組でしょうから、段数を減らせば『ェア(主に』の後ろに『Publisher』は入ります。
また和文と欧文では文字の揃え方の考えが異なり、縦組も横組もある和文は正方形のセンター基準でフォントデザインをしていたので、組み方もセンター揃えであったのが、欧文はベースラインを基準に文字を置いていくような活字の作りになっていました。その考え方は受け継がれている中で、現状では以下のような位置関係で和文と欧文の文字を混在させています。
実は和文フォントの中にも英数字が含まれていて、それらは和文中で記号などとして使うには揃いやすくデザインされています。例えば g j y などのディセンダ部分を短くするとか、 g h などはなるべく半角に近づける、大文字は全角に近づけるなどをしているために、 それらで欧文の文章を組むとダサい、キタナい、といわれることがあります。
逆に欧文の文字を和文中で使いすぎても、ところどころディセンダが行の下にはみ出すようなことがおき、目障りになることがあります。以下は括弧に全角和文のものと、欧文のものを使った例です。

また、同じ文字サイズでも和文フォントに対して欧文フォントは少し小さめなので、フォントサイズを変えなければバランスしないことがあります。和文フォント中に使用する欧文フォントをその都度指定するのも面倒なので、DTPでは「合成フォント」という機能があって、和文フォントと欧文フォントその他の組み合わせセットを作れるほか、組み合わせるフォントのサイズやベースライン・比率も個別に設定することができます。これを使えばデザインを崩さずに統一したフォント使いや、そのための設定が容易にできます。
Webフォントは印刷にも使えるのか?
Webフォントについては、記事「Webフォントにするメリットは何か?」に説明がありますが、CSS3.0 fonts moduleでサーバー側から提供されるフォントデータでクライアントが文字表示を行えるようになったものです。

Webフォントが使えると、ページ制作をしたオリジナルの姿で表示されるだけでなく、文字を画像にすることがなくなるので、文字検索、SEO対応、文字編集、自動翻訳、音声読み上げに対応できます。ただしWebブラウザがダウンロードして使うものなので、各ブラウザの機能や仕様に依存し、プリントやPDF化については、ブラウザが異なると出力結果は同じになりません。
つまりWebページやWeb制作とは関係なくWebフォントを使うのは難しいといえますが、PDF化したものを印刷物制作に取り込むようなことは工夫次第でできます。そもそも多くの場合にWebフォントを使う理由は、印刷用フォントをWEBでも使いたいことですので、日本語のフォントメーカーのものなら印刷用フォントを入手すればいいわけです。しかし上の図のように、欧文など日本で手に入らないフォントがWEBで使われていて、それを印刷したい場合もあります。
その場合、まずPDF保存してちゃんとWEBフォントが使えているかどうかを確認します。しかしそれを他の印刷物に転用できるかどうかは、フォント各社のライセンス条項によりますので、その確認が必要になります。日本のフォントベンダーはそれそれのサイトに注意書きがありますので確認してください。海外で一番有名なWEBフォント fonts.com では日本語フォントも取り扱っており、AXISフォントやDynaFont(ダイナフォント)がありますが、ライセンスや利用料金もかかるWebフォントもあります。
日本でポピュラーな欧文WEBフォントには、Google Fonts、Adobeフォントライブラリがあります。Google FontsはGoogleが提供している無料のフォントで、種類も豊富といった点が特徴です。Adobeフォントライブラリには幅広くデザイン性に富んだフォントが揃っていて、全体が全てのCreative Cloudのサブスクリプションプランで利用できます。
ロゴや商品名など短い文字列で使う場合、フォントとして再利用できなければ文字を画像化して使うしか方法がありません。利用できる場合はAdobeイラストレータに取り込んでアウトライン化することで使うという方法もあります。
Webフォントが使えると、ページ制作をしたオリジナルの姿で表示されるだけでなく、文字を画像にすることがなくなるので、文字検索、SEO対応、文字編集、自動翻訳、音声読み上げに対応できます。ただしWebブラウザがダウンロードして使うものなので、各ブラウザの機能や仕様に依存し、プリントやPDF化については、ブラウザが異なると出力結果は同じになりません。
つまりWebページやWeb制作とは関係なくWebフォントを使うのは難しいといえますが、PDF化したものを印刷物制作に取り込むようなことは工夫次第でできます。そもそも多くの場合にWebフォントを使う理由は、印刷用フォントをWEBでも使いたいことですので、日本語のフォントメーカーのものなら印刷用フォントを入手すればいいわけです。しかし上の図のように、欧文など日本で手に入らないフォントがWEBで使われていて、それを印刷したい場合もあります。
その場合、まずPDF保存してちゃんとWEBフォントが使えているかどうかを確認します。しかしそれを他の印刷物に転用できるかどうかは、フォント各社のライセンス条項によりますので、その確認が必要になります。日本のフォントベンダーはそれそれのサイトに注意書きがありますので確認してください。海外で一番有名なWEBフォント fonts.com では日本語フォントも取り扱っており、AXISフォントやDynaFont(ダイナフォント)がありますが、ライセンスや利用料金もかかるWebフォントもあります。
日本でポピュラーな欧文WEBフォントには、Google Fonts、Adobeフォントライブラリがあります。Google FontsはGoogleが提供している無料のフォントで、種類も豊富といった点が特徴です。Adobeフォントライブラリには幅広くデザイン性に富んだフォントが揃っていて、全体が全てのCreative Cloudのサブスクリプションプランで利用できます。
ロゴや商品名など短い文字列で使う場合、フォントとして再利用できなければ文字を画像化して使うしか方法がありません。利用できる場合はAdobeイラストレータに取り込んでアウトライン化することで使うという方法もあります。
zipファイルをWindowsとMac間でやりとりする方法
デザイナなどからMacのデータをzipファイルで受け取ってWindowsで開こうとすると、ファイル名が文字化けしていて上手く解凍できないことをよく聞きます。またDropboxやGoogle Driveで複数ファイルをダウンロードする場合は圧縮されてダウンロードされますが、この時も解凍すると文字化けしてしまう現象も同じ原理です。

これらの対策として、送る側で対処してもらう方法と、受けた側でツールを使って対応する場合があります。後者で有名なのはCubeICE(https://www.cube-soft.jp/cubeice/)というツールで、Windowsで作られたzipファイルをMacで解凍する場合の定番です。

Windowsで作られたzipファイルをMacで解凍する場合は、The Unarchiver(https://www.benricho.org/Tips/unarchiver/)があります。

しかしそもそもなぜこのようなMacとWindowsの違いがあるのでしょうか?それは日本語をコンピュータで扱う際の文字コードはJISで決まっているにもかかわらず、両OSとも当初はシフトJISを採用し、その後OSの改定の際にバラバラに「UTF-8」でエンコードに対応させてきたからです。つまりOSのバージョンによってそれぞれいろいろなやり方をとってきました。Windows10になって両OSとも「UTF-8」に揃いつつありますので、変換ツールなしでも文字化けなくやり取りする方法も生まれました。
Windowsでは2019年のアップデート(Version 1903)で、「メモ帳」アプリの文字コードでも既定でUTF-8が使われるようになりましたが、それ以前のメモ帳では「Shift-JIS」がデフォルトの文字コードでした。Windows10ではシステムに使われている文字コード(システムロケール)を、Shift-JISからUTF-8に変更することができ、そうすると今のMacOSと同じ土俵になり、文字化けは起こりません。しかし古いWindowsアプリでShift-JISでしか動かない場合は不具合が起こることがあります。
古いソフトウェア/アプリを使用しない場合は、コンピュータ環境が今後Webをベースとするクラウドへの移行しつつあり、UTF-8が主流になりますので、Shift-JISを使う環境を極力減らし、Windows10の設定をUTF-8にしていくことをおすすめします。

これらの対策として、送る側で対処してもらう方法と、受けた側でツールを使って対応する場合があります。後者で有名なのはCubeICE(https://www.cube-soft.jp/cubeice/)というツールで、Windowsで作られたzipファイルをMacで解凍する場合の定番です。
Windowsで作られたzipファイルをMacで解凍する場合は、The Unarchiver(https://www.benricho.org/Tips/unarchiver/)があります。
しかしそもそもなぜこのようなMacとWindowsの違いがあるのでしょうか?それは日本語をコンピュータで扱う際の文字コードはJISで決まっているにもかかわらず、両OSとも当初はシフトJISを採用し、その後OSの改定の際にバラバラに「UTF-8」でエンコードに対応させてきたからです。つまりOSのバージョンによってそれぞれいろいろなやり方をとってきました。Windows10になって両OSとも「UTF-8」に揃いつつありますので、変換ツールなしでも文字化けなくやり取りする方法も生まれました。
Windowsでは2019年のアップデート(Version 1903)で、「メモ帳」アプリの文字コードでも既定でUTF-8が使われるようになりましたが、それ以前のメモ帳では「Shift-JIS」がデフォルトの文字コードでした。Windows10ではシステムに使われている文字コード(システムロケール)を、Shift-JISからUTF-8に変更することができ、そうすると今のMacOSと同じ土俵になり、文字化けは起こりません。しかし古いWindowsアプリでShift-JISでしか動かない場合は不具合が起こることがあります。
古いソフトウェア/アプリを使用しない場合は、コンピュータ環境が今後Webをベースとするクラウドへの移行しつつあり、UTF-8が主流になりますので、Shift-JISを使う環境を極力減らし、Windows10の設定をUTF-8にしていくことをおすすめします。
Windowsで文字化けが起こる
CSVファイルをEXCELで開いたら文字化けしていたとか、メールが化けている、またメールの添付ファイルが化けているということが起こることがあります。また何らかのアプリケーションから取り出したファイルや、アプリケーションに読み込んだファイルが文字化けを起こすことがあります。典型的なのはWindowsで作成したテキストをメールに添付してiphoneで開いた場合などです。これは文字コードの違いによるもので、シフトJISで保存されていたものを、utf-8だと解釈して表示する場合に起こります。これに対しては、ファイルを取り出して文字コードの指定を変えれば正しく読みだすことができます。

以前はOSごとに基準となる文字コード体系が異なることによる現象が多くみられました。ms-dos以来パソコンのテキストファイルは無条件でシフトJISが使われてきましたが、現在主流のWindows10ではデフォルトでutf-8で保存するために、古いテキストファイルやcsvファイルをWindows10のアプリで開くと化けてしまう場合があります。

逆にWindows10で保存されたテキストをWindows7や古いアプリケーションで開くと、やはり化けてしまうことも起こります。しかしシフトJISであったり古いアプリで必ず文字化けが起こるかというと、そうとは限りません。それはブラウザでもアプリでもソフトウェア的に文字コードの判別をする機能を持っていて、自動変換をして正しく表示することも行われているからです。
自動変換に頼れない場合は、古いファイルやWindows10以前のアプリを使う場合には利用者側で文字コードの確認をしておくのがいいでしょう。今日ではutf-8に統一して扱うのが良いのですが、utf-8nとかBOM付があり、BOMはバイトオーダーマーク(byte order mark)の略で、Unicodeで符号化したテキストの先頭に付与され、アプリケーションによってはBOMで文字コード判断しますが、BOMがあると正常に処理できないこともあります。EXCELだけが対象ならBOM付の方がよいですが、Webで使うならBOM無しの方がおすすめです。

以前はOSごとに基準となる文字コード体系が異なることによる現象が多くみられました。ms-dos以来パソコンのテキストファイルは無条件でシフトJISが使われてきましたが、現在主流のWindows10ではデフォルトでutf-8で保存するために、古いテキストファイルやcsvファイルをWindows10のアプリで開くと化けてしまう場合があります。
逆にWindows10で保存されたテキストをWindows7や古いアプリケーションで開くと、やはり化けてしまうことも起こります。しかしシフトJISであったり古いアプリで必ず文字化けが起こるかというと、そうとは限りません。それはブラウザでもアプリでもソフトウェア的に文字コードの判別をする機能を持っていて、自動変換をして正しく表示することも行われているからです。
自動変換に頼れない場合は、古いファイルやWindows10以前のアプリを使う場合には利用者側で文字コードの確認をしておくのがいいでしょう。今日ではutf-8に統一して扱うのが良いのですが、utf-8nとかBOM付があり、BOMはバイトオーダーマーク(byte order mark)の略で、Unicodeで符号化したテキストの先頭に付与され、アプリケーションによってはBOMで文字コード判断しますが、BOMがあると正常に処理できないこともあります。EXCELだけが対象ならBOM付の方がよいですが、Webで使うならBOM無しの方がおすすめです。
「金伍萬圓」など漢字で数字を表す規則について
商取引の金額など、文字が改変されると困る場合に、字画の複雑な漢字を使うことがあります。よく証券などで「一」「二」「三」を「壱」「弐」「参」と書きますが、「四」以上になるとあまり知られていません。それは以下のような規則があったからだと思われます。
小切手振出等事務取扱規程 附則 (昭和四〇年四月一日大蔵省令第二〇号) 2
小切手の券面金額は、当分の間、所定の金額記載欄に、漢数字により表示することができる。この場合においては、「一」、「二」、「三」及び「十」の字体は、それぞれ「壱」、「弐」、「参」及び「拾」の漢字を用い、かつ、所定の金額記載欄の上方余白に当該金額記載欄に記載の金額と同額をアラビア数字で副記しなければならない。
供託規則 第六条
2 金銭その他の物の数量を記載するには、アラビア数字を用いなければならない。ただし、縦書をするときは、「壱、弐、参、拾」の文字を用いなければならない。
商業登記規則 第四十八条
2 金銭その他の物の数量、年月日及び番号を記載するには、「壱、弐、参、拾」の文字を用いなければならない。ただし、横書きをするときは、アラビヤ数字を用いることができる。
ちなみに、こういう漢数字の表記は、「大字(だいじ)」と呼ばれていて、日本では奈良時代から、中国では孟子の時代からあるそうで、4~9の漢字も決まっています。

旧字体の文章では、「廿、卅・丗」さらに縦棒を足した40という漢字も見かけましたが、それは書きやすいからだと言われています。もともと漢数字の一を十に書き換えるのを防止する目的で大字が使われて定着したことと、今では書きやすさという点ではアラビア数字が普及したので見かけなくなりました。時計のローマ数字もアラビア数字に変わっていったのと似ています。
小切手振出等事務取扱規程 附則 (昭和四〇年四月一日大蔵省令第二〇号) 2
小切手の券面金額は、当分の間、所定の金額記載欄に、漢数字により表示することができる。この場合においては、「一」、「二」、「三」及び「十」の字体は、それぞれ「壱」、「弐」、「参」及び「拾」の漢字を用い、かつ、所定の金額記載欄の上方余白に当該金額記載欄に記載の金額と同額をアラビア数字で副記しなければならない。
供託規則 第六条
2 金銭その他の物の数量を記載するには、アラビア数字を用いなければならない。ただし、縦書をするときは、「壱、弐、参、拾」の文字を用いなければならない。
商業登記規則 第四十八条
2 金銭その他の物の数量、年月日及び番号を記載するには、「壱、弐、参、拾」の文字を用いなければならない。ただし、横書きをするときは、アラビヤ数字を用いることができる。
ちなみに、こういう漢数字の表記は、「大字(だいじ)」と呼ばれていて、日本では奈良時代から、中国では孟子の時代からあるそうで、4~9の漢字も決まっています。
旧字体の文章では、「廿、卅・丗」さらに縦棒を足した40という漢字も見かけましたが、それは書きやすいからだと言われています。もともと漢数字の一を十に書き換えるのを防止する目的で大字が使われて定着したことと、今では書きやすさという点ではアラビア数字が普及したので見かけなくなりました。時計のローマ数字もアラビア数字に変わっていったのと似ています。
漢字にフリ仮名を自動でつけたい
簡単な名簿なら、WindowsのMicrosoftエクセルに漢字部分を入れて、その列にPHONETIC(フォネティック)関数を適用すれば、自動でカタカナが入ります。PHONETIC関数は、[関数の挿入]から、[関数の分類]で[情報]を選択すると、簡単に設定できます。
PHONETIC関数の結果と別の読み欲しいとか、フリガナとして表示される文字を修正したいときがあります。また、カタカナ表記を「ひらがな」表記のふりがなにしたい場合もあります。そのようなときは、「入力されている値のセル」を範囲選択して、ふりがなを表示させたり、設定を変更します。
同じエクセルでもMacのようにMicrosoftのかな漢字変換とは異なるものが入っている場合には、期待通りに動作しないという場合もあるようです。

また、一般の漢字交じり文章から、かなだけの文章にするには、異なるソフトウェアツールを使います。例えば『フリがなツール』(https://www.webtoolss.com/hiragana.html)を使うと、全部かな文字の文章にするだけでなく、「ふりがなレベル」が用意されていて、
小1以上の漢字に
小2以上の漢字に
小3以上の漢字に
小4以上の漢字に
小5以上の漢字に
小6以上の漢字に
中1以上の漢字に
常用漢字以上に
のような選択ができます。

表示の仕方は、ひらがな表記と、漢字の後ろに()でふりがなを振る表記が選べます。
プログラムによる自動変換は、例外的な表現には対応しない場合があるので、文字校正は必ず必要になります。
PHONETIC関数の結果と別の読み欲しいとか、フリガナとして表示される文字を修正したいときがあります。また、カタカナ表記を「ひらがな」表記のふりがなにしたい場合もあります。そのようなときは、「入力されている値のセル」を範囲選択して、ふりがなを表示させたり、設定を変更します。
同じエクセルでもMacのようにMicrosoftのかな漢字変換とは異なるものが入っている場合には、期待通りに動作しないという場合もあるようです。
また、一般の漢字交じり文章から、かなだけの文章にするには、異なるソフトウェアツールを使います。例えば『フリがなツール』(https://www.webtoolss.com/hiragana.html)を使うと、全部かな文字の文章にするだけでなく、「ふりがなレベル」が用意されていて、
小1以上の漢字に
小2以上の漢字に
小3以上の漢字に
小4以上の漢字に
小5以上の漢字に
小6以上の漢字に
中1以上の漢字に
常用漢字以上に
のような選択ができます。
表示の仕方は、ひらがな表記と、漢字の後ろに()でふりがなを振る表記が選べます。
プログラムによる自動変換は、例外的な表現には対応しない場合があるので、文字校正は必ず必要になります。
Webフォントにするメリットは何か?
Webの表示は利用者のPCなどにあるフォントを使うようにしていましたが、Webサイト側からすると紙面のデザインがどうなるか予想できないものでした。例えばwindowsの場合にOSの進化とともに標準搭載フォントが追加・変化してきました。
初期標準搭載 MSゴシック・MS明朝/MSPゴシック・MSP明朝/MS UI Gothic
Vistaから標準搭載 メイリオ
7から標準搭載 Meiryo UI
8.1から標準搭載 游ゴシック・游明朝
10から標準搭載 UDデジタル教科書体・Yu Gothic UI
さらに、Webはスマホやタブレットでも見られていて、Web表現のデザイン性を維持するためには、環境に依存しないフォント利用が必要になり、フォントデータをサーバーからダウンロードして表示するWebフォントが生まれました。特に欧文は非常に多くのデザインされたフォントが供給されています。


キヤノングローバルサイトは、本文も含めてWebフォントを使っています。またレンタルサーバで有名なサクラインターネットではモリサワのWebフォントサービス「TypeSquare」から33書体がWebサイトに無料で利用できます。
Webフォントは、文字数が少なくローディングの負荷が少ない欧文フォントで利用が広がったものの、文字数の多い日本語においてページごとにフォントをロードするのに若干時間がかかりましたが、最近ではネットの高速化と使用する文字だけをサブセット化して表示することで、利用面はかなり改善されています。Google Fontsも2014年から日本語フォントの無料提供をスタートしています。
Webフォントはブラウザの機能で表示するので、プリントやPDF化については、各ブラウザの機能や仕様に依存します。つまりブラウザが異なると出力結果は同じになりません。調整するにはブラウザで初期設定を変えるなどの手間がかかります。Webページを保存してプリントする場合には、CSSを書き換え、Webフォントをttfに変換する必要があり、そのようなサポートをするWebサイトもあります。また手持ちのフォントをWebフォントに変換してWebで使うためのコンバータなどもWeb上にあり、利用環境は整いつつあります。
Web制作会社の場合にはクライアントから依頼を受けて制作して納品するわけですが、その場合でもWebフォントは組み込めます。具体的には各フォント提供者の示す条件を見る必要があります。
初期標準搭載 MSゴシック・MS明朝/MSPゴシック・MSP明朝/MS UI Gothic
Vistaから標準搭載 メイリオ
7から標準搭載 Meiryo UI
8.1から標準搭載 游ゴシック・游明朝
10から標準搭載 UDデジタル教科書体・Yu Gothic UI
さらに、Webはスマホやタブレットでも見られていて、Web表現のデザイン性を維持するためには、環境に依存しないフォント利用が必要になり、フォントデータをサーバーからダウンロードして表示するWebフォントが生まれました。特に欧文は非常に多くのデザインされたフォントが供給されています。

キヤノングローバルサイトは、本文も含めてWebフォントを使っています。またレンタルサーバで有名なサクラインターネットではモリサワのWebフォントサービス「TypeSquare」から33書体がWebサイトに無料で利用できます。

Webフォントは、文字数が少なくローディングの負荷が少ない欧文フォントで利用が広がったものの、文字数の多い日本語においてページごとにフォントをロードするのに若干時間がかかりましたが、最近ではネットの高速化と使用する文字だけをサブセット化して表示することで、利用面はかなり改善されています。Google Fontsも2014年から日本語フォントの無料提供をスタートしています。
Webフォントはブラウザの機能で表示するので、プリントやPDF化については、各ブラウザの機能や仕様に依存します。つまりブラウザが異なると出力結果は同じになりません。調整するにはブラウザで初期設定を変えるなどの手間がかかります。Webページを保存してプリントする場合には、CSSを書き換え、Webフォントをttfに変換する必要があり、そのようなサポートをするWebサイトもあります。また手持ちのフォントをWebフォントに変換してWebで使うためのコンバータなどもWeb上にあり、利用環境は整いつつあります。
Web制作会社の場合にはクライアントから依頼を受けて制作して納品するわけですが、その場合でもWebフォントは組み込めます。具体的には各フォント提供者の示す条件を見る必要があります。
カタログの文字が汚くなる
画面でPDF校正をしている時にはくっきり見えたはずの小さな文字が、印刷物になってから見ると不鮮明になっていることがあります。一般的なカラー印刷はCyan(青)、Magenta(紅)、Yellow(黄)、Black(黒)の4色の組み合わせでいろいろな色を表現しているので、この4色およびそれらの重ねあわせであるRed(赤)、Green(緑)、BlueViolet(青紫)は画面と同様に鮮明に印刷されます。しかしこれら7色以外の色はベタではなく網点化されるので、文字も点の構成になることを免れません。

今日の印刷物では175線(1インチあたり)の網点になりますので、2ミリ以下の小さな文字の輪郭はかなり影響を受けてしまいます。画面では一様に見えるグレーでも印刷では黒に網がかかったものになりますので、写真のようにグレーに白文字の場合に画面で拡大したものと印刷したものでは大きな違いになります。

RGBのかけあわせを薄色にする場合も、家庭用インクジェットプリンタの校正では網点化されずに出力され、適度に滲むので点の構成が目立ちませんが、オフセットの網点印刷では文字の輪郭を完全には再現できません。

とりわけCMYと黒の4色が混じる中間色では色ごとに網の角度が変わるので、単純な点構成ではなく複雑な模様で構成されます。

この場合は、もし色ごとに版が少しずれて印刷されると、文字の輪郭はさらに不鮮明になります。

印刷の色校正用のプリンタでは印刷網点のシミュレーションをできるものがあって、事前にチェックできる場合があります。しかしこれらのことはオフセットの網点印刷の宿命的な課題なので、CMY黒など原色以外の小さな文字や罫線をシャープにを鮮明に印刷するには、必要な色のインキを特色として指定して、印刷版を増やすしかありません。パッケージやラベルなどの印刷機は掛け合わせではない特色が追加できるように6色~8色同時印刷できるようにしていて、この問題に対応しています。
一般の4色印刷にせざるを得ない場合は、紙面のデザイン上で小さな文字や罫線に薄色の掛けあわせが起こらないように配慮することになります。

今日の印刷物では175線(1インチあたり)の網点になりますので、2ミリ以下の小さな文字の輪郭はかなり影響を受けてしまいます。画面では一様に見えるグレーでも印刷では黒に網がかかったものになりますので、写真のようにグレーに白文字の場合に画面で拡大したものと印刷したものでは大きな違いになります。

RGBのかけあわせを薄色にする場合も、家庭用インクジェットプリンタの校正では網点化されずに出力され、適度に滲むので点の構成が目立ちませんが、オフセットの網点印刷では文字の輪郭を完全には再現できません。

とりわけCMYと黒の4色が混じる中間色では色ごとに網の角度が変わるので、単純な点構成ではなく複雑な模様で構成されます。

この場合は、もし色ごとに版が少しずれて印刷されると、文字の輪郭はさらに不鮮明になります。

印刷の色校正用のプリンタでは印刷網点のシミュレーションをできるものがあって、事前にチェックできる場合があります。しかしこれらのことはオフセットの網点印刷の宿命的な課題なので、CMY黒など原色以外の小さな文字や罫線をシャープにを鮮明に印刷するには、必要な色のインキを特色として指定して、印刷版を増やすしかありません。パッケージやラベルなどの印刷機は掛け合わせではない特色が追加できるように6色~8色同時印刷できるようにしていて、この問題に対応しています。
一般の4色印刷にせざるを得ない場合は、紙面のデザイン上で小さな文字や罫線に薄色の掛けあわせが起こらないように配慮することになります。
















新着情報





ランキング






